
08-llamaindex 数据加载和分割阶段小结
| 版本 | 内容 | 时间 |
|---|---|---|
| V1 | 新建 | 2026年04月21日23:16:01 |
下图展示的是 RAG 应用中数据预处理环节的核心架构——Ingestion Pipeline。理解这一阶段的关键,在于把握三个问题:数据怎么进来?进来后怎么切?切完后怎么标注?
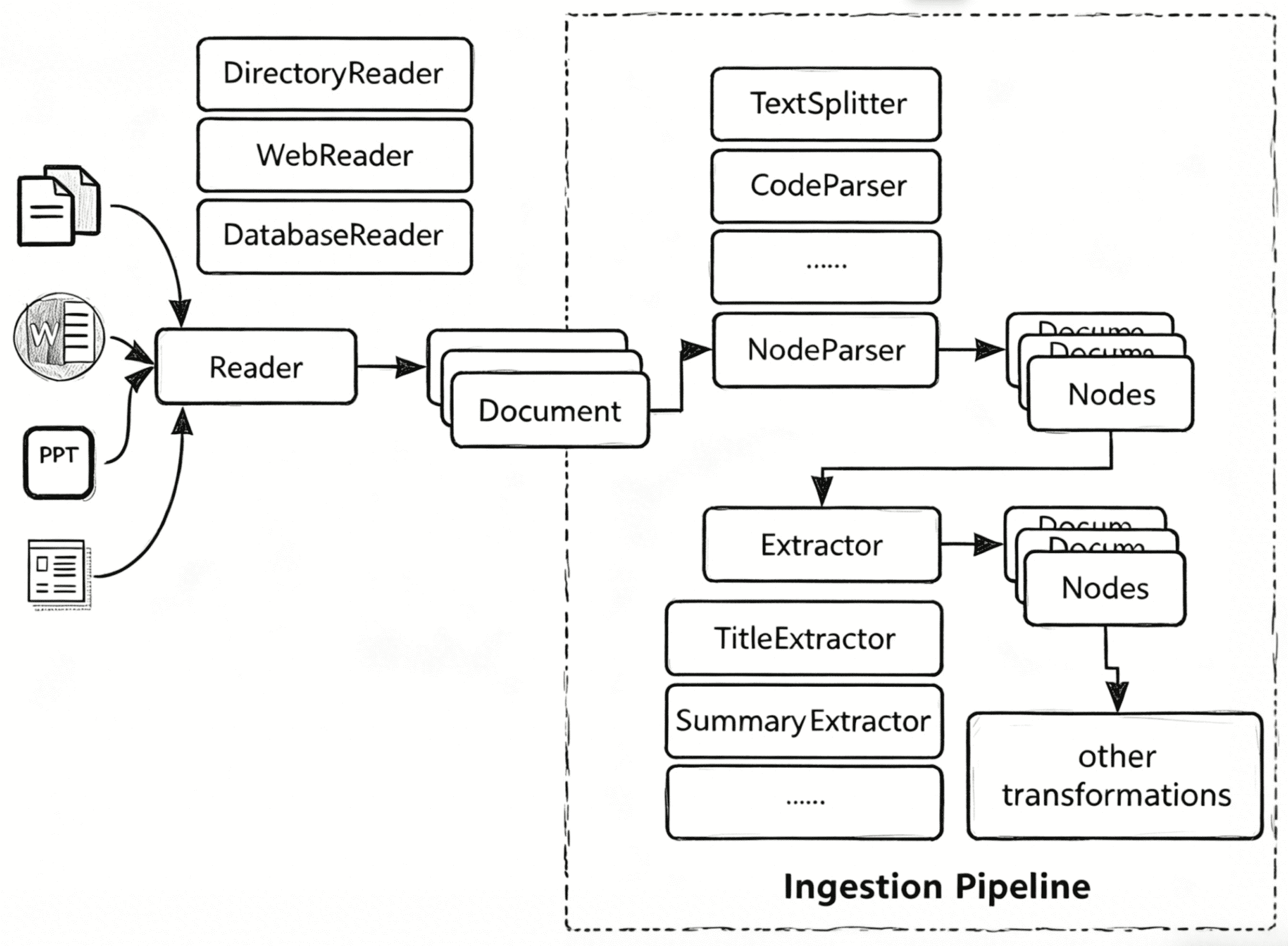
数据接入:Reader 的抽象价值
Reader 的核心价值在于统一数据接入口径。无论是本地文件(Word、PPT)、目录下的多文件、网页内容还是数据库记录,Reader 都将其抽象为 Document 对象。这种抽象使得上层管线无需关心数据来源的多样性。在实际工程中,一个 RAG 系统往往要接入企业知识库中的几十种格式(PDF、Markdown、HTML、Excel 等),Reader 的插件化设计让每种格式的解析逻辑彼此隔离,新增一种数据源只需添加一个 Reader 子类,不影响已有管线。
分割策略:NodeParser 的工程考量
NodeParser 是将 Document 拆为 Node 的关键组件,而分割策略直接决定 RAG 的检索质量。常见的分割方式包括:
- 字符数分割:简单粗暴,但可能在一个句子的中间被截断
- 语义分割:按段落、标题等语义边界切分,保留完整语义单元
- 递归分割:先按大段落分,超出阈值再按小段落递归切
- 结构感知分割:对代码按函数/类分割,对表格按行列分割
实践中没有"最优"分割粒度,需要在上下文完整性和检索精准度之间权衡。通常 Node 大小控制在 500-1000 token 之间,并保留一定的重叠区域(overlap),避免关键信息被切断。
元数据注入:Extractor 的赋能作用
Node 不仅仅是文本片段,还携带丰富的元数据。Extractor 负责自动从 Node 中提取或推断这些信息:
- TitleExtractor:推断该片段所属的文档标题或章节名
- SummaryExtractor:生成片段的摘要,便于检索时快速理解内容
- 还可以自定义抽取器提取关键词、实体、时间戳、来源 URL 等
元数据的价值体现在两个层面:检索阶段可基于元数据进行过滤(如"只搜 2024 年的文档");展示阶段可基于元数据提供溯源(如"该回答来自某文档第几节"),增强用户信任。
管线编排:Pipeline 的工业化能力
Ingestion Pipeline 是将上述组件串联为可执行流水线的装置。它不只是简单的组件拼接,还内置了多项工业化特性:
- 缓存设计:同一份文档重复入库时,通过内容哈希命中缓存,跳过已处理的 Node
- 持久化机制:处理中间结果可写入磁盘,中断后可断点续跑
- 并行处理:不同 Document 的解析可并发执行,充分利用多核资源
- 组件可插拔:Pipeline 中的转换器可灵活增删,例如在 Embedding 前插入一个去重转换器
总结
数据加载与分割看似是 RAG 的"前置工序",但实际决定了系统上限。Reader 的接入能力决定系统能覆盖多广的知识面,NodeParser 的分割质量决定检索能否命中正确内容,Extractor 的元数据丰富度决定检索能否精准过滤,而 Pipeline 的编排能力决定整个流程能否高效、稳定地运转。这一阶段的工程决策,往往比后续检索和生成环节的调参更为关键。