13-llamaindex 更多索引类型
| 版本 | 内容 | 时间 |
|---|---|---|
| V1 | 新建 | 2026年04月24日19:57:40 |
文档摘要索引
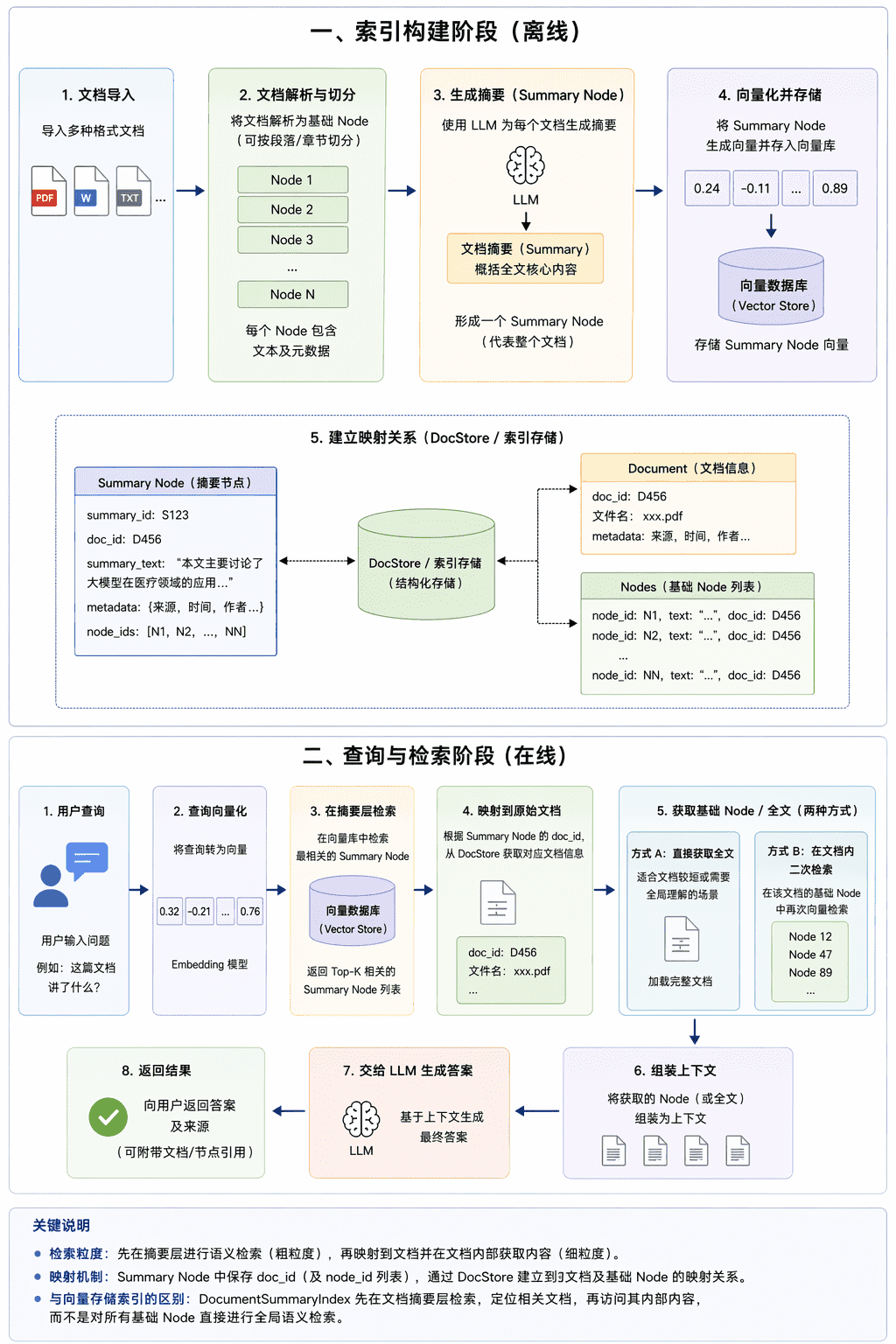
文档摘要索引(DocumentSummaryIndex)通过为每个文档构建摘要 Node,并对摘要进行向量化存储,从而提供基于文档级语义的检索能力。查询时首先在摘要层进行相似度匹配,以筛选相关文档;随后在命中的文档范围内访问或进一步检索基础 Node。
与向量存储索引(VectorStoreIndex)不同,文档摘要索引不执行跨文档的基础 Node 全局语义检索,而是采用“摘要检索 → 文档定位 → 内容访问”的两阶段检索机制。
核心原理
它的核心逻辑分为两步:“先概括,再检索”。
A. 构建索引阶段(Build)
当你调用 DocumentSummaryIndex.from_documents() 时,系统后台做了以下动作:
- 遍历文档:拿到每一篇完整的文档。
- LLM 生成摘要:系统会调用大模型(LLM),根据你提供的
summary_query(比如:“这段文本主要讲了什么?”),生成一段摘要文本。 - 向量存储:调用 Embedding 模型,将这段摘要文本转化为向量,存入向量数据库。
- 原文存储:将原始文档的内容(切分后的 Nodes)存入文档存储(DocStore),并与摘要的 ID 建立映射。
关键点:索引里存的是“文档摘要的向量”,而不是“原文片段的向量”。
B. 查询检索阶段(Query)
当你提问时(例如:“帮我总结一下那篇关于 RAG 的文章”):
- 向量化查询:将你的问题转化为向量。
- 摘要匹配:在向量数据库中搜索与问题最相似的文档摘要。
- 获取原文:找到匹配的摘要后,系统知道这篇摘要对应的完整原文在哪里,把整篇文档(或相关段落)取出来。
- 生成回答:将取出的完整原文作为上下文,送给 LLM 生成最终答案。
核心优势
它解决了 VectorStoreIndex(普通向量索引)的一个痛点:“只见树木,不见森林”。
| 对比维度 | VectorStoreIndex (普通向量索引) | DocumentSummaryIndex (摘要索引) |
|---|---|---|
| 索引对象 | 把文档切碎,按**段落(Chunk)**存向量 | 按整篇文档生成摘要,存摘要向量 |
| 检索逻辑 | 找最相似的几个句子 | 找最相似的整篇文章 |
| 适用场景 | “在这个段落里,具体的数字是多少?” (细节查询) | “这篇文章主要讲了什么核心观点?” (宏观总结、跨段落逻辑分析) |
| 上下文窗口 | 只把检索到的片段给 LLM,可能丢失上下文 | 把检索到的整篇文档给 LLM,上下文完整 |
通俗理解:
- VectorStoreIndex 像是在图书馆的索引卡片里找关键词,找到的是几页纸。
- DocumentSummaryIndex 像是先读了每本书的序言/简介,通过简介找到最合适的那本书,然后把整本书拿来读。
案例
llm = Ollama(model='qwen:0.5b')
embed_model = OllamaEmbedding(model_name="qwen3-embedding:0.6b", embed_batch_size=50)
Settings.embed_model = embed_model
Settings.llm = llm
# 构造几个模拟的 Document 对象
documents = [
Document(text="""
☀️ 我家有个行走的小太阳,名叫乐乐 🐾
是一只有着“焦糖色”大衣的金渐层少爷,
眨眼已经两岁啦!🎂
从当初的一小坨,长成了现在圆润Q弹的大煤气罐。
虽然已经是个两岁的“大孩子”了,
但依然保留着那份没心没肺的快乐,
每天在沙发上跑酷、踩奶、呼呼大睡。
看着他那双铜铃般的大眼睛,感觉一天的疲惫都被治愈了。✨
愿你的喵生,永远只有罐头和小鱼干,永远做快乐的小猫咪!💛
""",
metadata={"category": "动物", "topic": "cat"}, doc_id="doc1"),
Document(text="浩浩是一只很惨很惨的乌龟,他每次都舔而不得,长的也不难看,但是被甩的次数太多了,还是个 ATMer",
metadata={"category": " 动物", "topic": "乌龟"}, doc_id="doc2"),
]
# 使用持久化客户端
chroma_client = chromadb.PersistentClient(path="./chroma_storage/chroma_db")
collection = chroma_client.get_or_create_collection("index_collection_test9")
vector_store = ChromaVectorStore(chroma_collection=collection)
# 设置文本分割器和元数据提取器的 标题提取器
splitter = SentenceSplitter(chunk_size=200, chunk_overlap=10)
extractor = TitleExtractor()
# 设置向量存储
storage_context = StorageContext.from_defaults(vector_store=vector_store)
summary_index = DocumentSummaryIndex.from_documents(documents=documents,
show_progress=True,
transformations=[splitter, extractor],
storage_context=storage_context,
summary_query="用中文描述所给文本的主要内容,同时预设可以回答的一些问题。")
pprint.pprint(summary_index.get_document_summary("doc1"))输出
('文本主要内容:介绍宠物“乐乐”的一些信息。\n'
'可以回答的问题:\n'
'1. "乐乐"是什么样的?\n'
'2. "乐乐"有什么特别的地方吗?\n'
'3. 对于“乐乐”来说,它最喜欢做什么?\n'
'4. 对于“乐乐”来说,它的主人是谁?')什么时候用它
- 文档结构复杂:当你需要回答的问题依赖于整篇文章的逻辑,而不是某一句话(比如“总结这篇财报的风险因素”)。
- 检索召回率低:当你发现 VectorStoreIndex 只能搜到零散的句子,导致 LLM 答非所问时,用它来锁定整篇正确的文档。
- 混合使用:最佳实践通常是结合使用。用
DocumentSummaryIndex先选出最相关的 1-3 篇文档,然后再用VectorStoreIndex在这几篇文档里进行精细化搜索。
对象索引
核心概念与解决什么问题
问题场景:假设你想检索的不是"文本片段",而是任意 Python 对象——比如一个图片对象、一个 Pandas DataFrame、一个音频文件引用、一个自定义的 Cat 类实例等。这些对象本身没有 embedding,无法直接存入向量数据库进行语义检索。
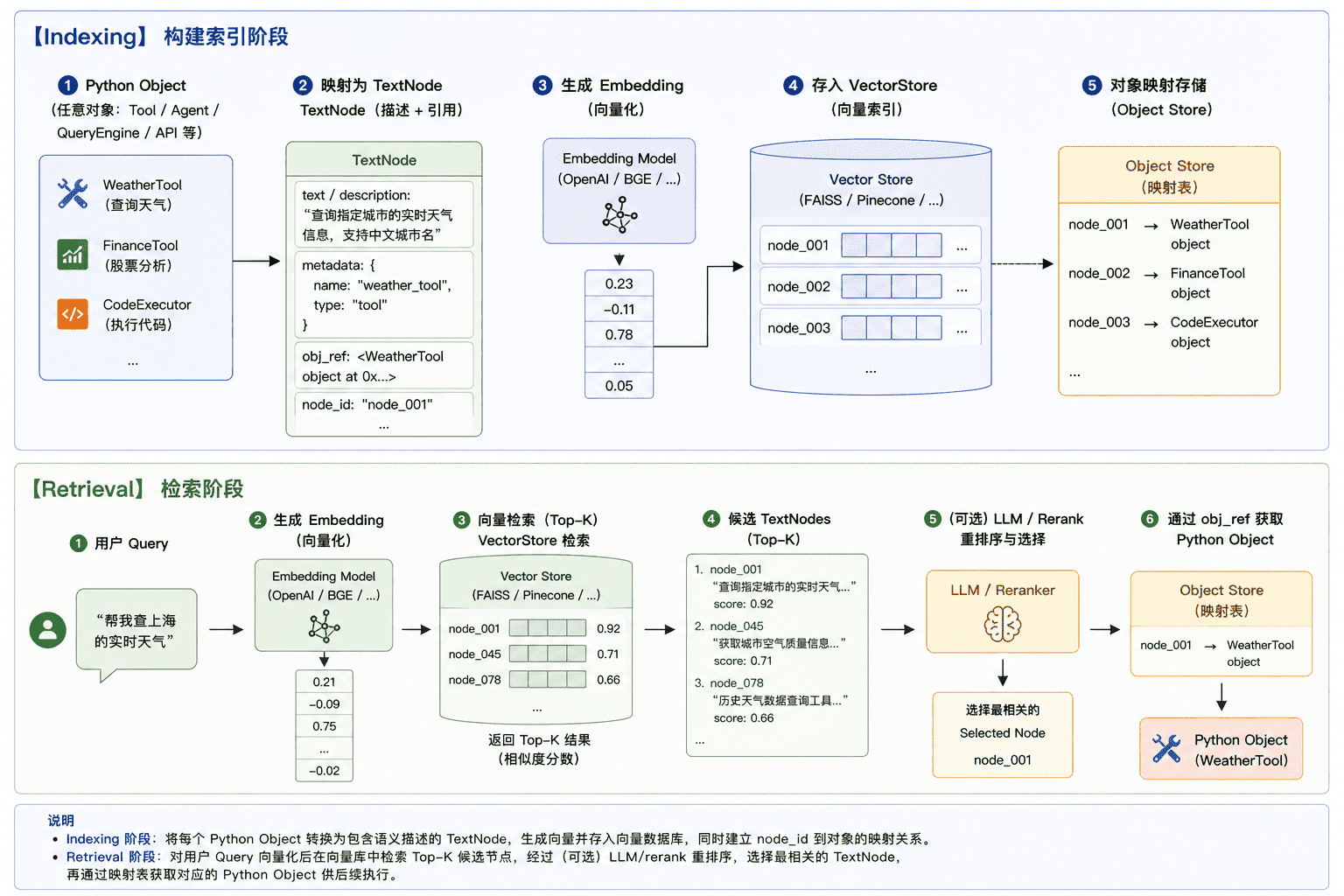
ObjectIndex 的作用:将任意 Python 对象 → 映射为带文本表示的 Node → 通过向量索引进行检索 → 检索结果反序列化回原始对象。
原理
与普通向量存储索引不同,对象索引本身并不直接负责数据的嵌入和检索,而是依赖于其他索引(如向量存储索引)来完成底层的 Node 节点操作。因此,在创建对象索引时,必须传入一个 VectorStoreIndex 实例作为底层支撑。与此同时,为了让向量存储索引检索到的 Node 对象能够还原为原始对象,需要引入 ObjectNodeMapping 来维护两者之间的映射关系。该对象承担两个核心职责:
- 将原始对象转换为可被向量存储索引检索的 Node 对象。
- 检索完成后,根据返回的 Node 对象反向查找并还原出原始对象。
采用了 SimpleObjectNodeMapping 来实现这一映射机制。在将原始对象转为 Node 对象时,它通过 str() 方法把对象序列化为字符串,进而构建出一个 TextNode:
def to_nodes(self, objs: Sequence[OT]) -> Sequence[TextNode]:
return [self.to_node(obj) for obj in objs]
def to_node(self, obj: Any) -> TextNode:
return TextNode(id_=str(hash(str(obj))), text=str(obj))另外,SimpleObjectNodeMapping 在初始化时还会建立字符串到原始对象的反向映射:
def __init__(self, objs: Optional[Sequence[Any]] = None) -> None:
objs = objs or []
for obj in objs:
self.validate_object(obj)
self._objs = {hash(str(obj)): obj for obj in objs}借助这个映射表,当向量存储索引返回 Node 对象后,只需提取其文本内容并计算 hash 值,即可通过映射表快速定位并返回对应的原始对象。
案例
llm = Ollama(model='qwen:0.5b')
embed_model = OllamaEmbedding(model_name="qwen3-embedding:0.6b", embed_batch_size=50)
Settings.embed_model = embed_model
Settings.llm = llm
# 构造一些不同类型的普通对象
obj1 = {"team": "火箭", "city": "休斯顿", "championships": 2, "mvp": "哈登"}
obj2 = ["PyTorch", "TensorFlow", "JAX", "PaddlePaddle"]
obj3 = (["训练", "验证", "测试"], [80000, 10000, 10000])
obj4 = "Transformer架构通过自注意力机制实现序列数据的并行处理"
objs = [obj1, obj2, obj3, obj4]
# 使用持久化客户端
chroma_client = chromadb.PersistentClient(path="./chroma_storage/chroma_db")
collection = chroma_client.get_or_create_collection("index_collection_test11")
vector_store = ChromaVectorStore(chroma_collection=collection)
# 构造对象索引(内部自动完成 对象→Node→embedding→向量存储)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
object_index = ObjectIndex.from_objects(
objs,
index_cls=VectorStoreIndex,
storage_context=storage_context,
show_progress=True,
)
# 构造一个检索器,测试检索结果
object_retriever = object_index.as_retriever(similarity_top_k=1)
result = object_retriever.retrieve("哈登")
print(f'results:{result}')输出
results:[{'team': '火箭', 'city': '休斯顿', 'championships': 2, 'mvp': '哈登'}]知识图谱索引
概念
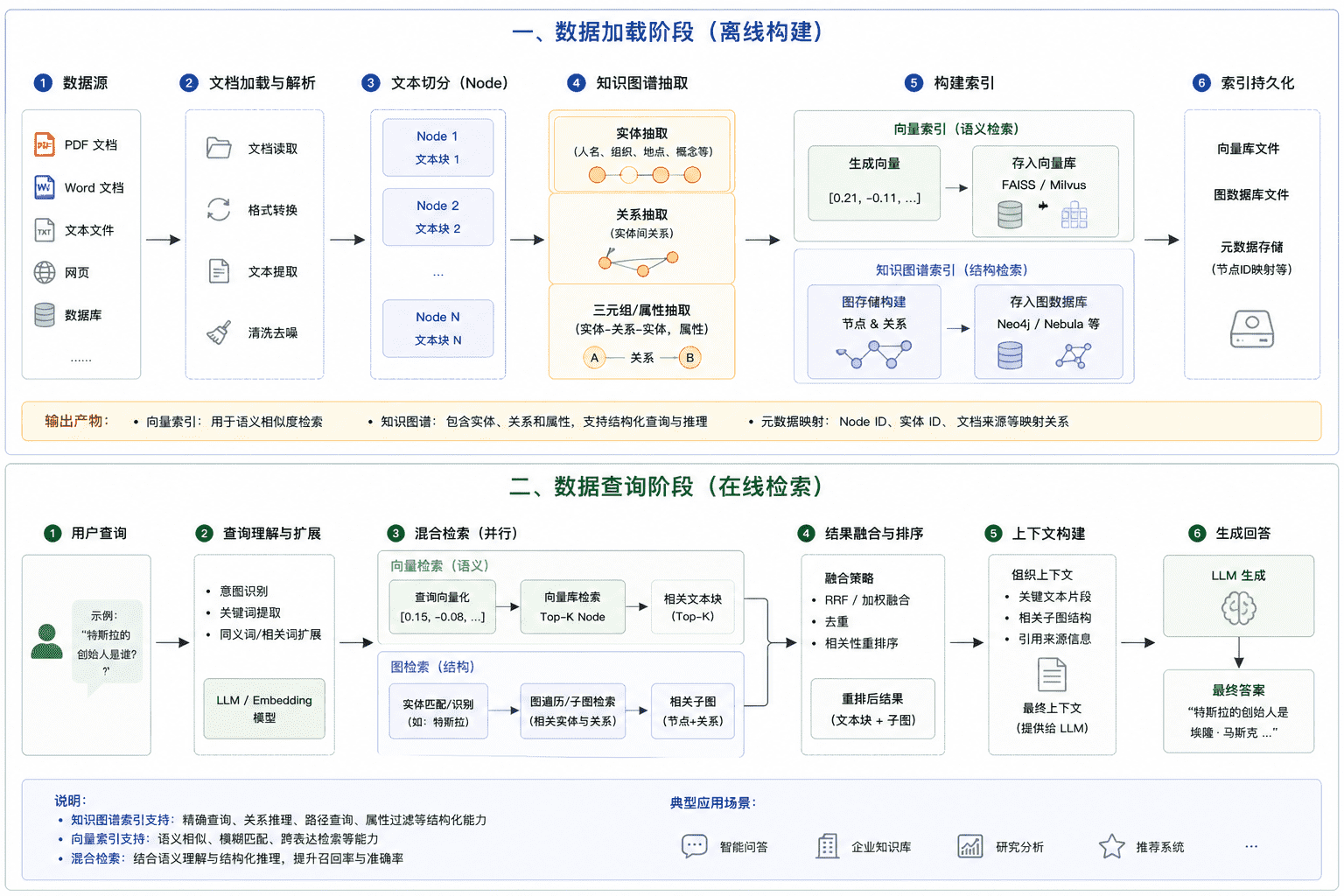
知识图谱索引是 LLamaIndex 中将非结构化文本转化为结构化图谱数据的索引类型。与传统向量索引的根本区别在于数据的组织方式:向量索引是扁平的向量集合,而知识图谱索引是有向属性图(节点 + 边 + 属性)。
知识图谱的数据来源通常是海量的结构化与非结构化文档,通过对这些文档进行抽取、融合和加工,最终转化为大量形如"实体-关系-实体"的三元组形式(实体可附带多个属性),从而支撑后续的存储与应用。
演进历史:
KnowledgeGraphIndex(旧版,v0.10.53 起已废弃):使用简单的字符串三元组(主语, 谓语, 宾语),无类型信息PropertyGraphIndex(新版):使用带类型的EntityNode/ChunkNode和带标签的Relation,支持属性图模型,兼容 Neo4j 等图数据库
知识图谱索引(PropertyGraphIndex)与向量存储索引(VectorStoreIndex)的构建方式相似,均通过 from_documents 方法完成,且底层存储均可替换,但两者在核心逻辑上存在两点关键差异:
一是底层存储不同。向量索引使用 VectorStore(如 ChromaDB),知识图谱索引使用 PropertyGraphStore(如 SimplePropertyGraphStore 或 Neo4j)。
二是索引构建流程不同。VectorStoreIndex 的流程是:为每个 Node 生成 embedding 向量,将文本内容和向量存入向量库,建立向量到原文的映射。PropertyGraphIndex 的流程是:借助 LLM 从 Node 内容中提取实体与关系,形成"实体-关系-实体"三元组,存入 PropertyGraphStore,并保留三元组与原始 Node 的映射。
简言之,向量索引的核心是"语义向量化",而知识图谱索引的核心是"结构化知识抽取"。用户还可通过 kg_extractors 参数自定义实体关系的提取策略。
原理
案例
内容
郭大垸是一座历史悠久的水乡古镇,位于我国的中部地区。这片土地有着丰富的自然水系和田园风光,总面积约为3000平方公里,常住人口超过50万。这里是我国重要的农业、渔业和传统手工业基地之一。郭大垸有一座古老的学府,成立于清末民初,历经百年风雨,培养了大批扎根基层、服务乡梓的优秀人才。这所学府致力于传承耕读文化,注重知行合一的教育理念,为地方的繁荣发展输送了源源不断的生力军。郭大垸的水产养殖业发展迅速,拥有多个现代化渔业示范区,吸引了众多科研机构和龙头企业入驻。这些企业涵盖了淡水养殖、水产品深加工、冷链物流等多个领域,为区域经济注入了强劲动力。在郭大垸的中心区域,有一座底蕴深厚的民俗博物馆,馆内珍藏了大量反映水乡人民生产生活的实物资料,包括古老的渔船、渔具、农具和生活用品,生动展现了这片土地从围湖造田到乡村振兴的发展变迁。此外,博物馆还定期举办非遗技艺展示和民俗文化活动,吸引了大批游客前来参观学习。郭大垸还拥有多处知名景点,如蜿蜒的江堤、葱郁的防护林、古朴的村落和热闹的集镇码头。这些景点吸引了大量游客前来观光体验,为当地旅游业带来了蓬勃生机。郭大垸周边,还有多个现代农业产业园,出产丰富的农产品,如莲藕、菱角、鱼虾和特色稻米等。这些农产品在国内外市场上享有盛誉,为区域的农业现代化发展提供了有力支撑。代码
llm = Ollama(model='qwen2.5:7b')
embed_model = OllamaEmbedding(model_name="qwen3-embedding:0.6b", embed_batch_size=50)
Settings.embed_model = embed_model
Settings.llm = llm
documents = SimpleDirectoryReader(
input_files=["../../data/郭大垸.txt"],
).load_data()
# 指定知识图谱的存储,这里使用内存存储
property_graph_store = SimplePropertyGraphStore()
storage_context = StorageContext.from_defaults(
property_graph_store=property_graph_store
)
# 构造知识图谱索引(这里进行了本地化存储)
if not os.path.exists("./storage/graph_store"):
index = PropertyGraphIndex.from_documents(
documents,
storage_context=storage_context,
)
index.storage_context.persist(persist_dir="./storage/graph_store")
else:
print("Loading graph index...")
index = load_index_from_storage(
StorageContext.from_defaults(
persist_dir="./storage/graph_store"
)
)
# pprint.pprint(index.__dict__)
# pprint.pprint(index.property_graph_store.__dict__)
# 构造查询引擎
query_engine = index.as_query_engine(
include_text=True,
similarity_top_k=2,
)
response = query_engine.query(
"介绍一下郭大垸的信息吧",
)
print(f"Response: {response}")输出
Response: 郭大垸是一座历史悠久的水乡古镇,位于我国中部地区。这里自然水系丰富,田园风光优美,总面积大约3000平方公里,居住着超过50万的人口。郭大垸不仅是重要的农业、渔业基地,也是传统手工业的重要基地。该地有一所古老的学府,这所学校自清末民初成立以来,一直致力于培养服务于地方的人才,并且重视耕读文化的传承以及知行合一的教育理念。
郭大垸的水产养殖业非常发达,建有多个现代化渔业示范区,吸引了许多科研机构和龙头企业加入其中,这些企业在淡水养殖、水产品深加工及冷链物流等方面都有涉猎,极大地推动了当地的经济发展。此外,在郭大垸还设有一座民俗博物馆,里面收藏了许多反映当地人民生活与生产的珍贵文物,如传统的渔船、渔具等,生动展示了这片土地的历史变迁。博物馆还会定期举办非物质文化遗产技艺展示和其他民俗文化活动,吸引了很多游客前来参观学习。
郭大垸还有不少知名的旅游景点,例如蜿蜒曲折的江堤、郁郁葱葱的防护林带、古色古香的小村落以及繁忙热闹的集市码头等,这些都使得郭大垸成为了一个颇受欢迎的旅游目的地。周边区域还分布着多个现代农业产业园,生产出各种优质农产品,包括莲藕、菱角、鱼虾以及特色稻米等,在国内外市场上享有良好声誉,为促进区域农业现代化做出了重要贡献。树索引
概念
树索引是一种层次化的索引结构。构建时,利用 LLM 对 Node 列表逐层生成摘要,递归自底向上形成树形结构——叶子 Node 为原始文本,父 Node 为子节点摘要,顶层为根 Node(Root Node)。构建过程可通过参数控制,仅在叶子 Node 数量达到阈值时才生成上级 Node。检索时根据模式返回不同层级的 Node,可能是概括全局的根 Node,也可能是具体细节的叶子 Node。
原理
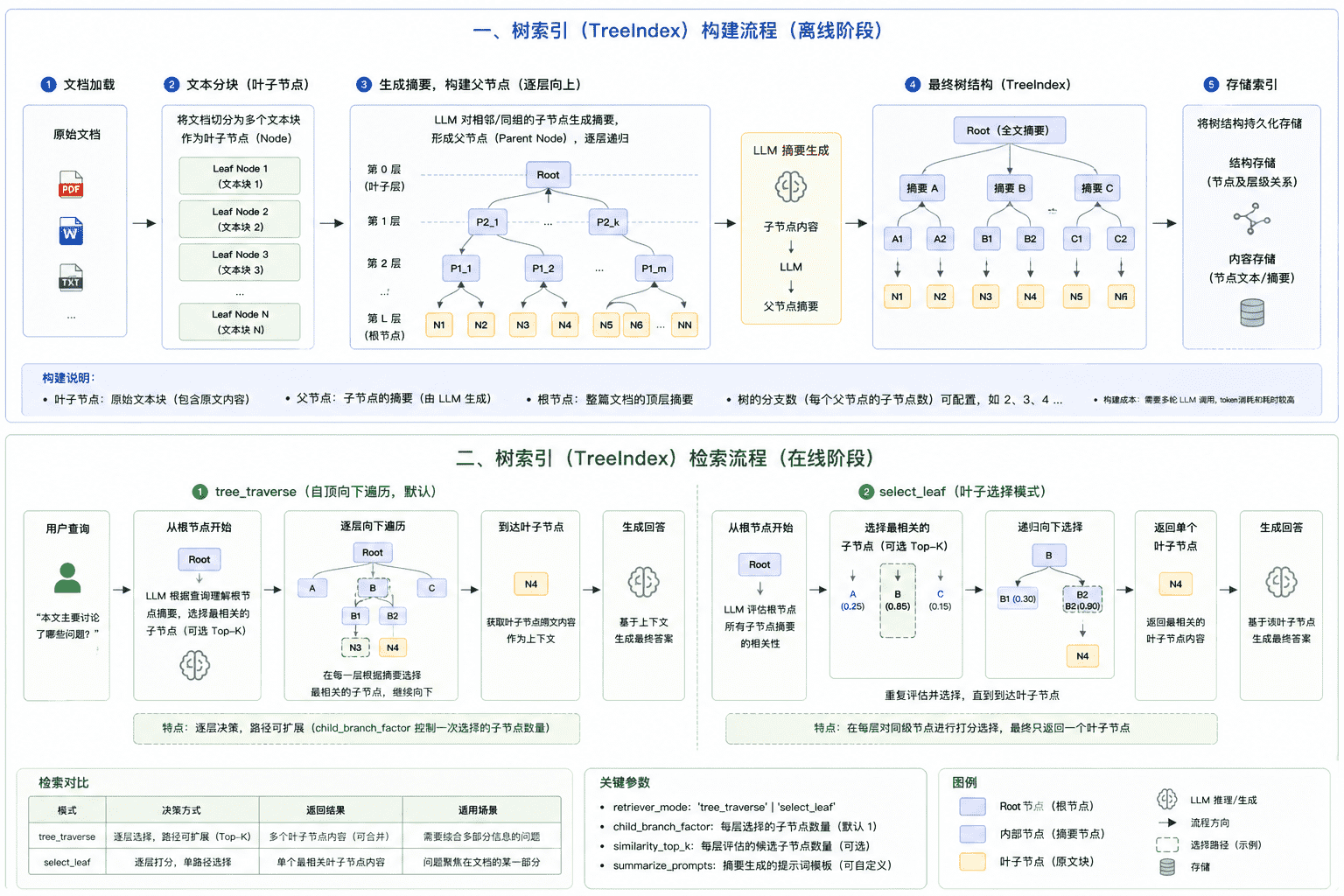
案例
llm = Ollama(model='qwen:0.5b')
embed_model = OllamaEmbedding(model_name="qwen3-embedding:0.6b", embed_batch_size=50)
Settings.embed_model = embed_model
Settings.llm = llm
documents = SimpleDirectoryReader(
input_files=["../../data/郭大垸.txt"],
).load_data()
sentence_splitter = SentenceSplitter(chunk_size=200, chunk_overlap=10)
nodes = sentence_splitter.get_nodes_from_documents(documents)
# 构造树索引
index = TreeIndex(nodes=nodes, num_children=2)
# 打印索引结构
print(index.index_struct)从打印的索引结构中可以看到,除了保存正常的根 Node 和叶子 Node,还会保存父子 Node 的映射关系(node_id_to_children_ids) ,即每个 Node 所对应的叶子 Node,然后通过简单的迭代,就可以形成一棵用于检索的索引树。
树索引在检索时会默认根据输入问题检索相关的叶子 Node,但是可以指定不同的检索方式和参数,比如是用向量相似度检索, 还是用大模型判断检索,是检索根 Node 还是检索叶子 Node,以及需要检索返回的 Node 数量等。
{
"index_id": "f3e6066f-a1f9-4388-95da-00a0f505cef5",
"summary": null,
"all_nodes": {
"0": "ac1e6211-bf08-48b3-9c3c-3fff9d632836",
"1": "438074d7-1cf1-4b4a-aedc-b36e6c0b3693",
"2": "f1c3521e-b932-47c6-9657-f10f9732e58d",
"3": "885cb124-280c-4c4c-b110-d9a38d0cca7f",
"4": "bb3ce391-e342-42db-8ae6-dcbc0748cd60",
"5": "95349b40-3894-4e68-a860-4e21c8abc8ea",
"6": "dd675c23-a269-4ae0-b5ea-4e4f904b6ec9",
"7": "be39c352-d8a5-4bc2-aca8-b86b25dcfa43",
"8": "2ca96853-2ead-4234-b52c-fef4dc67da36",
"9": "5c7ebd32-39e1-47ef-9651-80bbfb4af6a4"
},
"root_nodes": {
"8": "2ca96853-2ead-4234-b52c-fef4dc67da36",
"9": "5c7ebd32-39e1-47ef-9651-80bbfb4af6a4"
},
"node_id_to_children_ids": {
"ac1e6211-bf08-48b3-9c3c-3fff9d632836": [],
"438074d7-1cf1-4b4a-aedc-b36e6c0b3693": [],
"f1c3521e-b932-47c6-9657-f10f9732e58d": [],
"885cb124-280c-4c4c-b110-d9a38d0cca7f": [],
"bb3ce391-e342-42db-8ae6-dcbc0748cd60": [],
"95349b40-3894-4e68-a860-4e21c8abc8ea": [
"ac1e6211-bf08-48b3-9c3c-3fff9d632836",
"438074d7-1cf1-4b4a-aedc-b36e6c0b3693"
],
"dd675c23-a269-4ae0-b5ea-4e4f904b6ec9": [
"f1c3521e-b932-47c6-9657-f10f9732e58d",
"885cb124-280c-4c4c-b110-d9a38d0cca7f"
],
"be39c352-d8a5-4bc2-aca8-b86b25dcfa43": [
"bb3ce391-e342-42db-8ae6-dcbc0748cd60"
],
"2ca96853-2ead-4234-b52c-fef4dc67da36": [
"95349b40-3894-4e68-a860-4e21c8abc8ea",
"dd675c23-a269-4ae0-b5ea-4e4f904b6ec9"
],
"5c7ebd32-39e1-47ef-9651-80bbfb4af6a4": [
"be39c352-d8a5-4bc2-aca8-b86b25dcfa43"
]
}
}关键词表索引
概念
本质是一个倒排索引(类似搜索引擎/哈希表):
keyword1 → {node_id_1, node_id_3, node_id_7}
keyword2 → {node_id_2, node_id_5}
keyword3 → {node_id_1, node_id_7}每个 Node 提取出关键词集合,建立 keyword → node_id 集合 的映射。检索时,从查询中提取关键词,通过关键词找到对应的 Node,按匹配关键词数量排序返回。
原理
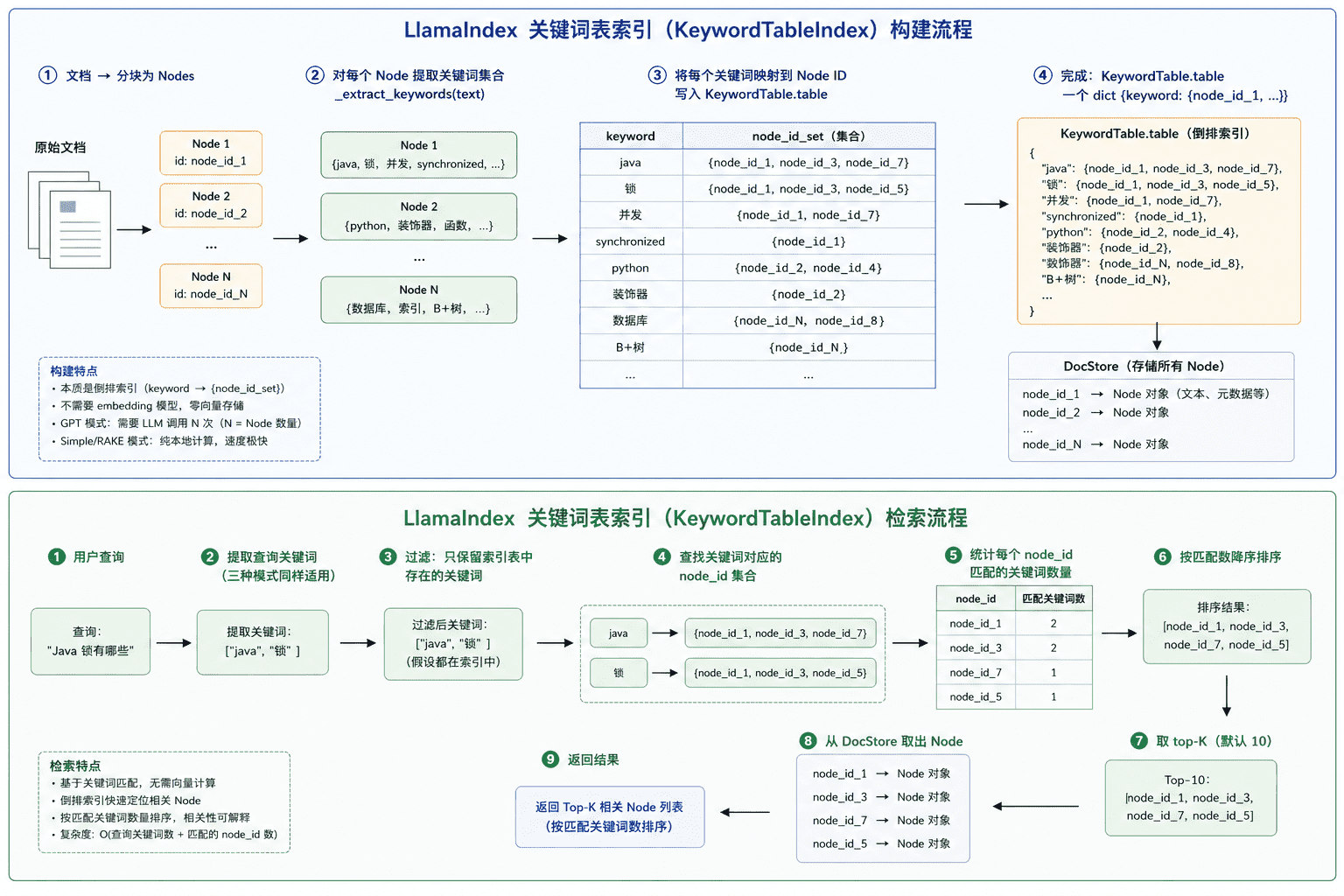
关键词的提取
| 类名 | 关键词提取方式 | 是否需要 LLM |
|---|---|---|
KeywordTableIndex | LLM 根据 prompt 生成关键词列表 | ✅ |
SimpleKeywordTableIndex | 正则 \w+ 提取单词 + TF 排序 + 停词过滤,但目前这种方法通过识别空格来区分单词,因此暂时只能用于英文输入。 | ❌ |
RAKEKeywordTableIndex | RAKE 算法提取关键词短语 | ❌ |
案例
llm = Ollama(model='qwen:0.5b')
embed_model = OllamaEmbedding(model_name="qwen3-embedding:0.6b", embed_batch_size=50)
Settings.embed_model = embed_model
Settings.llm = llm
documents = SimpleDirectoryReader(
input_files=["../../data/郭大垸.txt"],
).load_data()
sentence_splitter = SentenceSplitter(chunk_size=200, chunk_overlap=10)
nodes = sentence_splitter.get_nodes_from_documents(documents)
# 构造关键词表索引,用大模型智能提取内容关键词
table_index = KeywordTableIndex(nodes)
print(table_index.index_struct)
engine = table_index.as_query_engine()
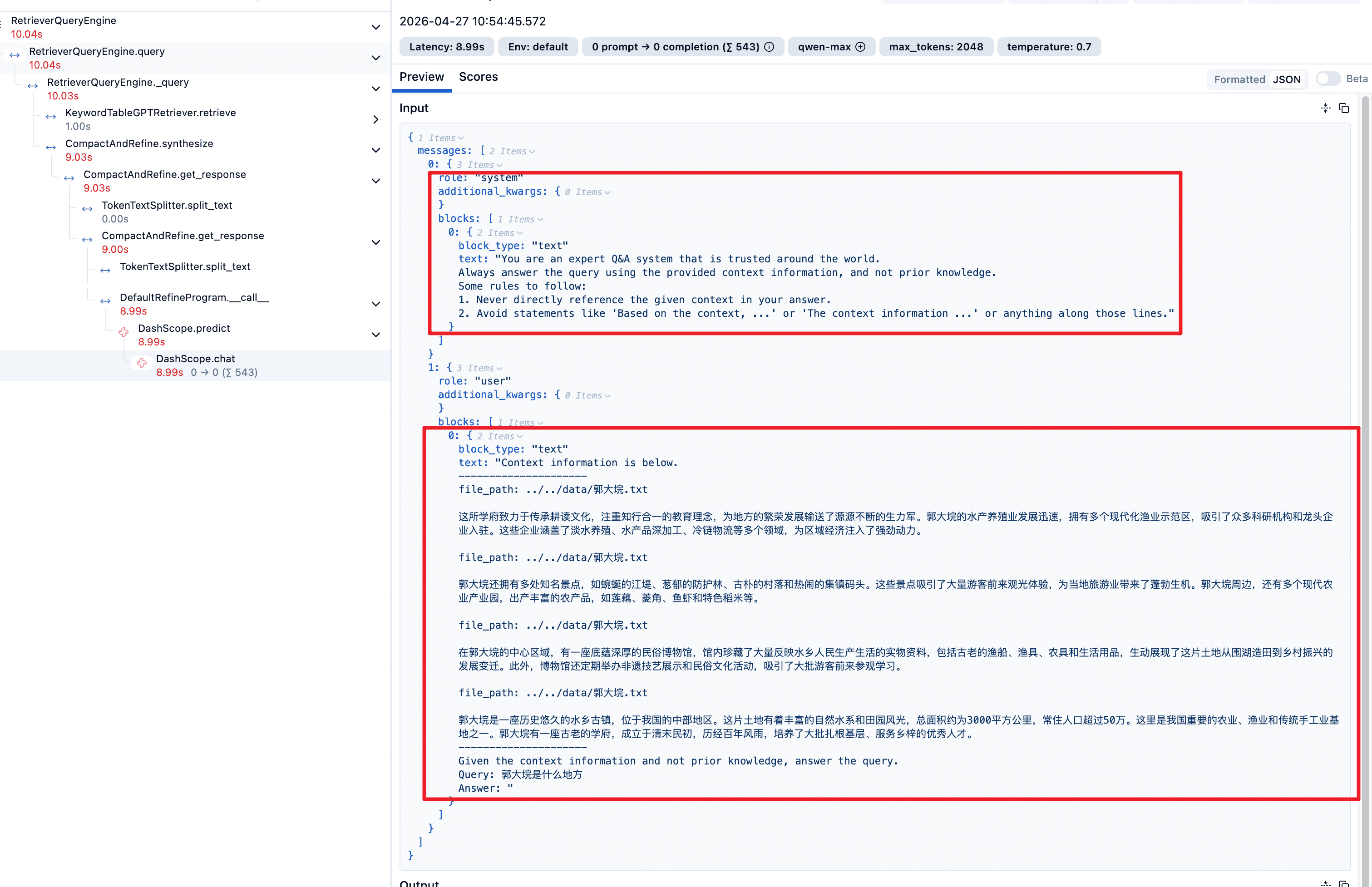
result = engine.query("郭大垸是什么地方")
print(result)输出
郭大垸是一座历史悠久的水乡古镇,位于我国的中部地区。这里拥有丰富的自然水系和田园风光,总面积约为3000平方公里,常住人口超过50万。郭大垸是我国重要的农业、渔业和传统手工业基地之一。Langfuse 链路