
08-Tree of Thoughts
| 版本 | 内容 | 时间 |
|---|---|---|
| V1 | 新建 | 2026年03月26日14:29:41 |
思维树(ToT)是什么?
思维树是思维链(CoT)的高阶升级版本,是针对超高复杂度问题的提示词工程框架,核心是让大语言模型像人类解决复杂问题时一样:先提出多种可能的推理思路(生成分支),再评估每个思路的可行性(剪枝),可行则继续推导,不可行则回溯换思路(回退),最终从所有可行路径中找到最优解。
- 简单类比:解迷宫时,不只是一条路走到黑(CoT),而是先看所有可能的岔路(生成分支),排除明显走不通的路(剪枝),对可能走通的路继续探索,走不通就退回到上一个岔路换方向(回溯)。
- 核心关键词:思维树(多分支推理)、自我评估(剪枝)、搜索算法(BFS/DFS)、前瞻 + 回溯(策略性探索)。
大语言模型(LLMs)各类问题求解方法的示意图如下。每个矩形框代表一个思维单元(thought),即一段连贯的文本序列,作为问题求解过程中的中间步骤。
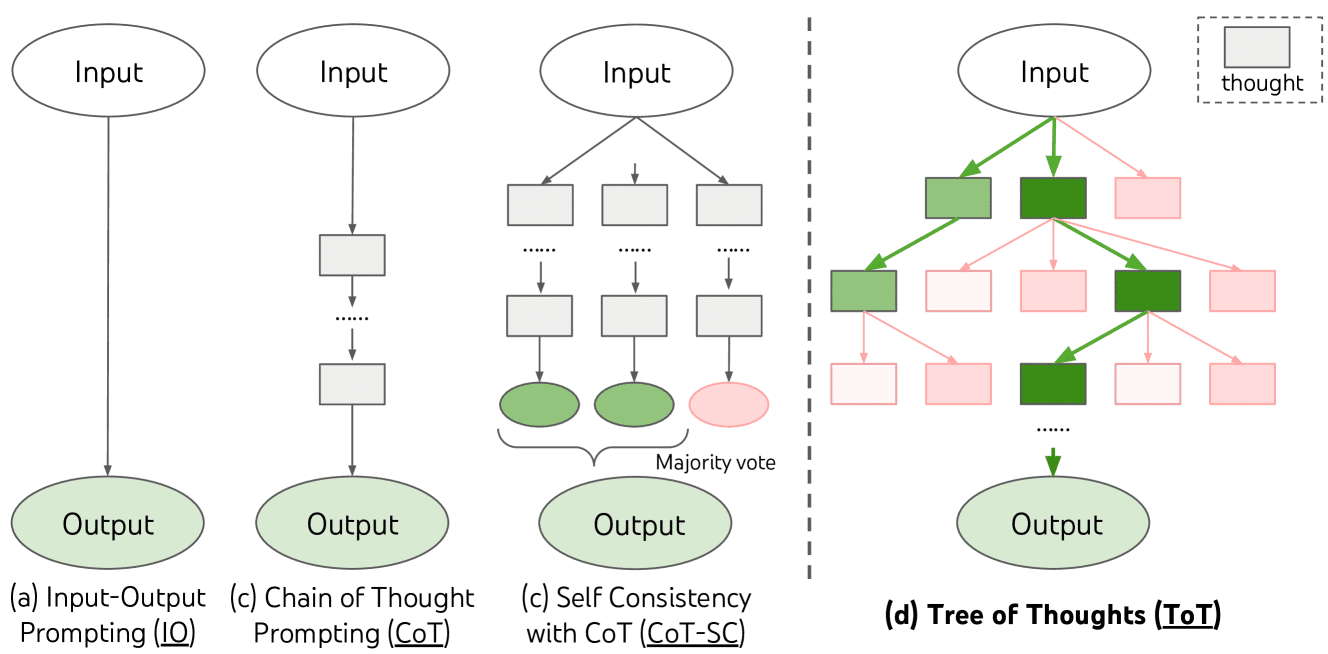
论文:
ToT 与 CoT(思维链)的核心区别
| 特性 | 思维链(CoT) | 思维树(ToT) |
|---|---|---|
| 推理形式 | 单一线性推理:一步接一步推导,只有一条路径 | 多分支树状推理:每一步生成多个候选思路,形成思维分支 |
| 错误处理 | 一步错则后续全错,无回溯能力 | 可评估错误思路并回溯,换分支重新推理 |
| 评估能力 | 无显式自我评估,仅靠分步推导减少错误 | 主动对中间思维自我评估,筛选可行思路 |
| 搜索策略 | 无专门搜索算法,靠自然语言分步推进 | 结合 BFS/DFS 等搜索算法,系统性探索解空间 |
| 适配任务 | 中等复杂度推理(如多步算术、简单逻辑) | 超高复杂度推理(如 24 点、博弈、复杂规划) |
性能比较
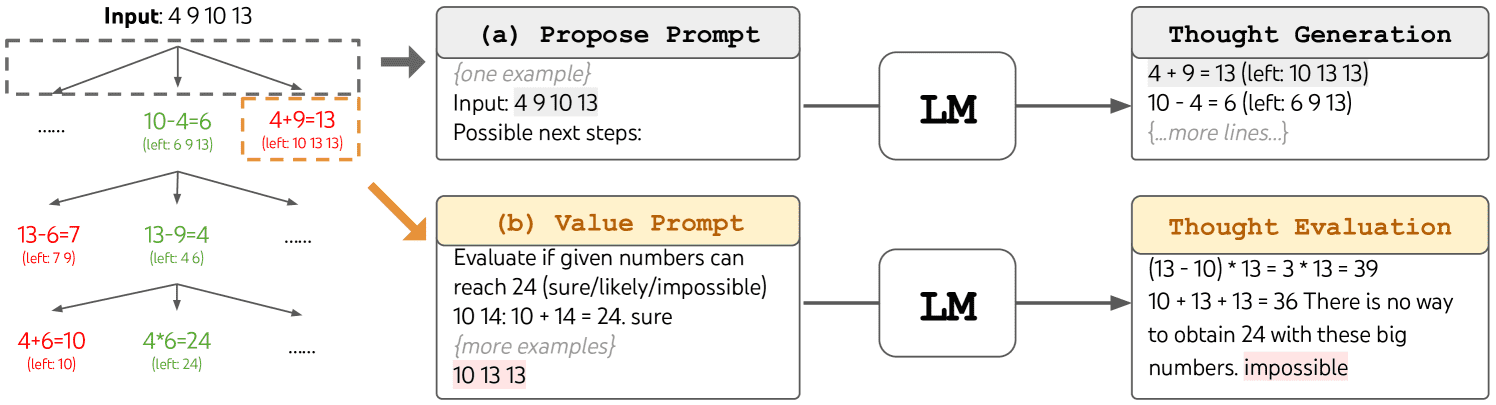
使用思维树框架时,不同任务需要定义候选思维的数量和思维 / 步骤的数量。例如,论文中以24 点游戏这一数学推理任务为例,该任务要求将推理思维拆解为 3 个步骤,每个步骤都需推导一个中间等式,且每一步会保留最优的 5 个候选思维。
在 24 点游戏任务中运用思维树执行广度优先搜索(BFS) 时,会通过提示词引导模型将每个候选思维评估为**「确定可行 / 可能可行 / 完全不可行」** 三个等级,以此判断该思维能否推导出 24 的最终结果。正如作者所述:「此举旨在筛选出经少量前瞻验证即可判定为正确的局部解,依据「数值过大 / 过小」的常识排除完全不可行的局部解,其余则归为「可能可行」。」每个思维会经过 3 次采样验证,具体过程见下文示意图。
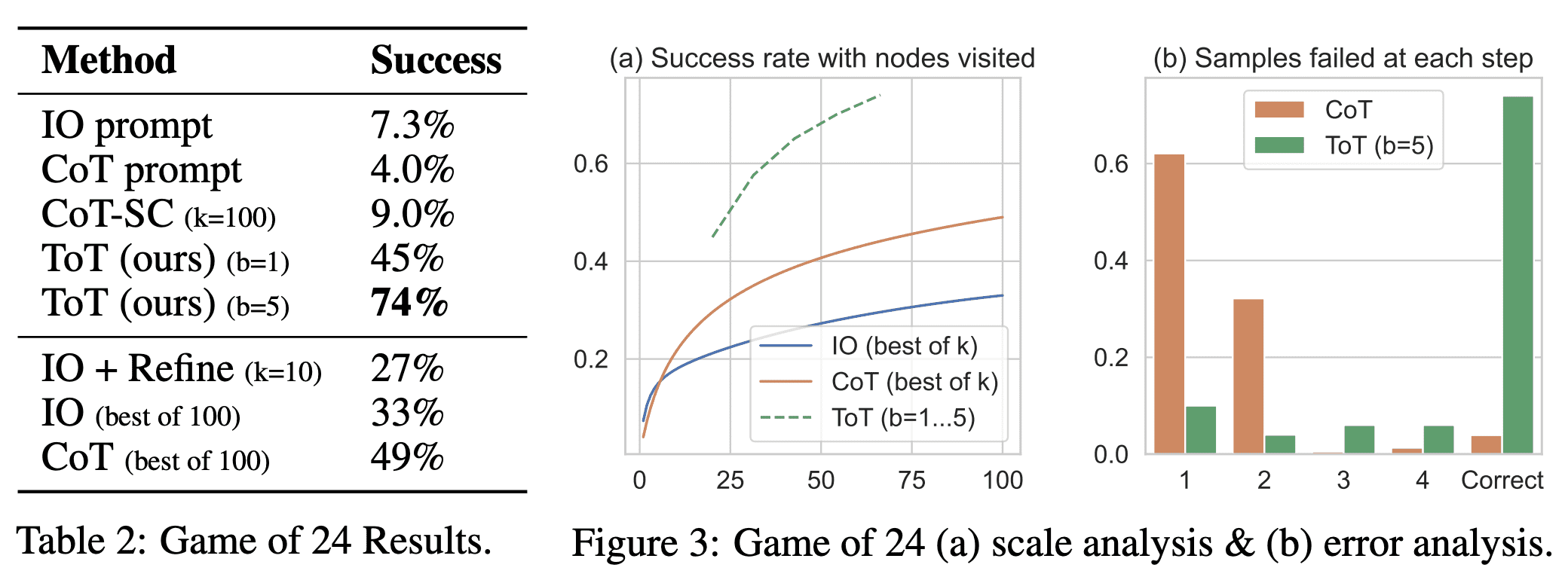
从下图所示结果可以看出,ToT 的性能明显优于其他提示方法:
两种主流 TOT 的区别
https://arxiv.org/abs/2305.10601 和 https://arxiv.org/abs/2305.08291 的主要思想是类似的。都是让大模型别再「一条路走到黑」推理,而是通过多轮对话的方式,像树一样生出多个推理分支,再从分支里找正确答案,最终目的都是让大模型更会解复杂问题。
核心区别:谁来「指挥」树状搜索?怎么定搜索规则?核心在**「什么时候回头换思路、回头退几步、选哪个分支继续推」**
前者用「现成的通用算法」指挥,直接用了计算机里早就有的DFS(深度优先)、BFS(广度优先)、束搜索这些通用搜索算法,让这些算法来定搜索规则。比如 BFS 就是「把当前步的所有推理分支都看一遍,再走下一步」,DFS 就是「认准一个分支走到头,走不通再退回去换分支」。
👉 特点:通用、简单、不用额外训练,但这些算法是「死规则」,不会根据具体问题调整 —— 解 24 点、下象棋、做规划,用的都是同一套规则,对特定问题没针对性,效率不高。
后者用「AI 控制器」指挥,智能、能自己学,专门做了一个 「ToT Controller」(相当于一个小 AI),还通过强化学习把这个控制器训练好了,让它来定搜索规则。这个控制器会自己判断:这个分支走不通了,该退几步?当下哪个分支最有希望,该选哪个?
👉 特点:专属指挥、智能适配,这个控制器还能自己学习进化—— 比如从新的题目里学经验,甚至自己和自己练(就像阿尔法狗自己和自己下棋提升一样)。
TOT简化版的提示词
Imagine three different experts are answering this question.
All experts will write down 1 step of their thinking,
then share it with the group.
Then all experts will go on to the next step, etc.
If any expert realises they're wrong at any point then they leave.
The question is...新模型太聪明,会自动 “优化掉” 它觉得没必要的推理过程。只有用强格式 + 分步骤强制,才能逼它演完整的推演流程。
严格按照以下格式执行,不得省略任何内容,不得提前给出答案,必须完整输出所有步骤:
【规则】
同时模拟专家A、专家B、专家C三位独立专家。
第一步:只输出三位专家的第一步推理,不许得出最终答案。
第二步:基于第一步,输出三位专家的第二步推理。
任何专家发现错误必须标注“退出讨论”。
全程不许合并、不许简写、不许提前总结。
问题:我6岁时妹妹年龄是我的一半,我现在70岁,妹妹多少岁?