
09-Retrieval Augmented Generation (RAG)
| 版本 | 内容 | 时间 |
|---|---|---|
| V1 | 新建 | 2026年03月26日16:42:17 |
RAG(检索增强生成),本质是解决大语言模型「知识老旧、容易胡编(幻觉)、专业知识不足」的核心技术,也是现在 AI 应用开发中最常用的技术之一。下面从核心定义、解决的问题、工作原理、优势、实际效果五个方面介绍。
RAG 是什么?
RAG 是由 Meta AI 提出的大模型增强技术,核心是把「信息检索」和「大模型生成」结合起来:让大模型回答问题前,先从外部知识库(比如维基百科、企业文档、行业数据库)里搜出和问题相关的真实资料,再结合这些资料生成答案,而不是只靠自己训练时记住的老旧知识瞎编。
简单说:普通大模型是 “凭记忆答题”,RAG 增强的大模型是 “先翻书 / 查资料,再结合资料答题”。
RAG 解决的核心问题
RAG 的设计初衷 —— 普通大模型能搞定简单任务(比如情感分析、命名实体识别),但面对复杂、需要专业 / 最新知识的任务时,会暴露 3 个严重问题,RAG 就是专门治这 3 个问题的:
- 知识静态老旧:大模型的知识都是训练时的 “死知识”,训练完就不会更新(比如 2025 年训练的模型,不知道 2026 年的新事件 / 新数据);
- 容易产生幻觉:不懂的问题会瞎编答案,还编得理直气壮,缺乏事实一致性;
- 专业知识不足:面对法律、医疗、金融等知识密集型领域,仅靠自身训练知识远远不够。
RAG 的核心工作原理
RAG 的执行流程固定且简单,全程分 3 步,不用重新训练大模型,只需要对接外部知识库,这也是它的最大优势:
1)步骤 1:接收问题,检索外部资料
模型拿到用户的问题后,先通过检索组件(类似 AI 版的搜索引擎),从提前准备的外部知识库(比如维基百科、本地文档库)里,搜出和问题高度相关的资料 / 文档;
2)步骤 2:拼接资料,作为提示词上下文
把搜出来的相关资料,和用户的原始问题拼在一起,形成带真实资料的新提示词(相当于给模型加了 “参考资料”);
3)步骤 3:结合资料,生成最终答案
大模型基于「原始问题 + 相关参考资料」生成答案,全程以外部资料为依据,不再只靠自身记忆。
把大模型的自身训练知识称为参数化记忆(死知识、静态),把外部知识库称为非参数化记忆(活知识、可随时更新),RAG 就是让大模型同时用这两种记忆答题。
论文:https://arxiv.org/pdf/2005.11401 中的图如下:
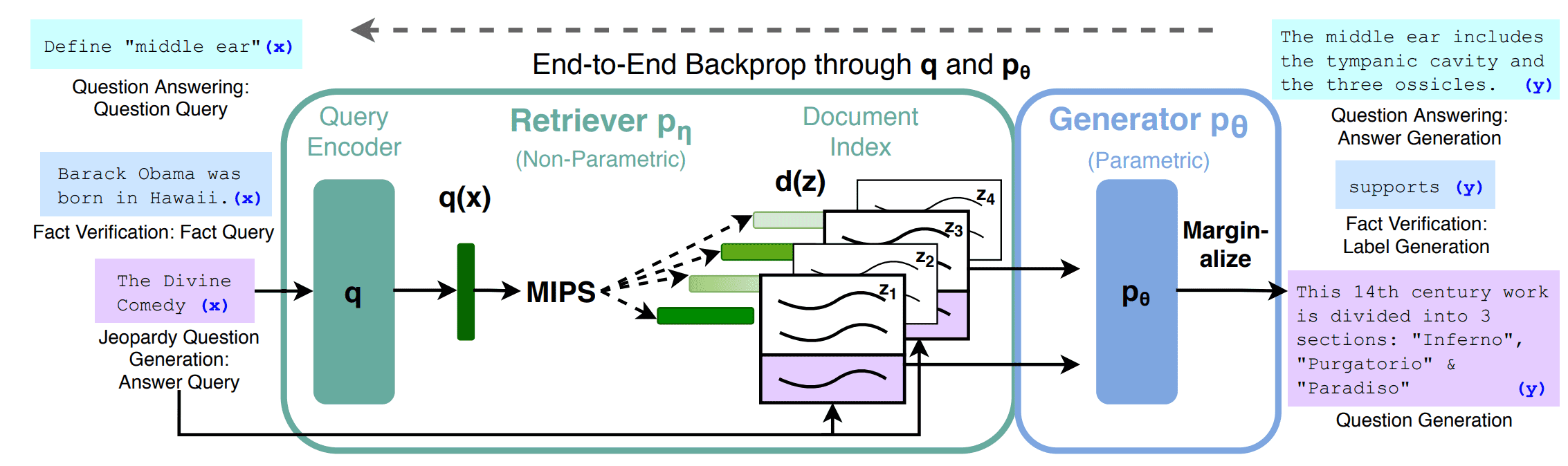
RAG 技术的底层实现框架,本质是把「检索器」和「生成器」两个预训练模型拼在一起优化,再用固定算法完成「搜资料→用资料生成答案」的核心流程,拆解成5 个关键部分:
- 核心操作:预训练检索器 + 预训练 seq2seq 模型 → 端到端微调
- 预训练检索器:专门干「搜资料」的 AI,由查询编码器和文档索引两部分组成(下文会拆),是 RAG 的「搜书工具」;
- 预训练 seq2seq 模型(生成器):专门干「写答案」的大模型(比如 GPT、BART 这类),是 RAG 的「答题笔」;
- 端到端微调:把这两个预训练好的模型拼在一起,用同一批数据一起训练优化,让「搜资料」和「写答案」的动作高度适配(比如检索器知道生成器需要什么类型的资料,生成器能精准利用检索器找到的资料),而不是两个模型各自为战。
- 检索器的两个核心组件:Query Encoder + Document Index
这是「搜资料」的核心,缺一不可,类比成图书馆的检索系统就懂了:
- Query Encoder(查询编码器):把用户的问题(比如「RAG 的工作原理」)转换成计算机能理解的向量(数字串),相当于把你的问题「翻译成图书馆的检索语言」;
- Document Index(文档索引):提前把外部知识库的所有资料(比如维基百科、专业文档)都转换成向量,再按规则整理好形成向量库,相当于图书馆里「按类别排好、标好检索码的藏书库」。
- 怎么搜:Maximum Inner Product Search (MIPS) 找 top-K 文档zi
- MIPS(最大内积搜索):最常用的「向量匹配算法」—— 比较「问题的向量」和「所有资料的向量」的内积值,内积值越高,说明二者相关性越强,相当于图书馆检索系统「按相似度排序找书」;
- top-K 文档*zi*:只选相似度最高的前K篇资料(K是可设置的数字,比如前 5、前 10 篇),避免找太多资料导致生成答案时信息冗余,相当于「只拿和问题最相关的几本书」。
- 隐变量(latent variable):把检索到的文档集合z当成 “看不见的关键变量”
简单说:最终的答案y,完全依赖于检索器找到的资料*z*—— 找的资料不同,答案就不同;但资料z是检索器 “随机” 找出来的(比如不同次搜同一问题,可能找到略有差异的 top-K 资料),属于模型内部看不见、但能影响结果的变量,所以叫「隐变量」。
- 怎么生成最终答案:对不同文档的预测结果做「边缘化求和」
这是 RAG 保证答案准确性和鲁棒性的关键,不是只拿某一篇资料让生成器写答案,而是让生成器基于每一篇检索到的 top-K 资料,各自生成一个初步答案,再通过「边缘化求和」的算法,把这些初步答案做加权融合(相关性越高的资料,对应的初步答案权重越大),最终得到一个综合所有优质资料的最终答案y。
→ 相当于:找 5 本最相关的书,分别根据每本书写一个答案,再把这 5 个答案按书的相关性高低,整合出一个最全面、最准确的答案。
一句话总结:
用预训练的 “搜资料 AI”+“写答案 AI” 组队,经联合优化后,先通过向量匹配找最相关的前 K 篇资料,再结合所有资料的信息加权生成最终答案—— 这就是 RAG 技术最经典的底层实现逻辑,也是保证 RAG「搜得准、答得真」的核心。
RAG 的核心优势
- 彻底减少幻觉,答案更真实:答案有外部资料作为依据,不再瞎编,大幅提升事实一致性和可靠性;
- 知识可实时更新,不用重训模型:想让模型掌握新知识 / 新数据,只需要更新外部知识库就行,不用花巨资重新训练大模型,效率极高、成本极低;
- 适配知识密集型任务:完美解决法律、医疗、金融、科研等需要专业 / 最新知识的复杂任务;
- 生成的答案更具体、更多元:相比普通大模型的泛泛而谈,RAG 结合具体资料,答案会更贴合事实、细节更丰富。
RAG 的典型适用场景
只要是需要真实知识、最新知识、专业知识的场景,RAG 都能发挥作用,典型场景包括:
- 智能问答机器人:企业知识库问答、产品客服问答、行业知识问答(比如医疗科普、法律咨询);
- 内容生成:结合专业资料写论文、写行业报告、写产品文案;
- 事实验证:判断网络信息的真假、验证新闻 / 论文中的数据;
- 智能检索:结合大模型的理解能力,实现对非结构化文档(比如 PDF、Word)的智能搜索和问答。
总结
RAG 是大模型的 “外置大脑 + 实时知识库”,通过「先检索外部真实资料,再结合资料生成答案」的方式,彻底解决大模型知识老旧、容易胡编的问题,是现在打造高可靠性 AI 应用的必备核心技术。